 Avris
Avris
 Avris
Avris

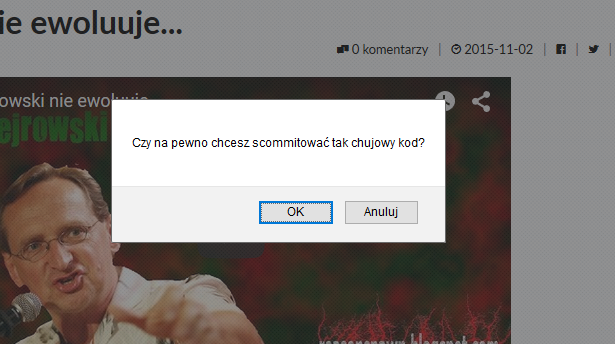
Proste zadanie: umieścić na stronie przycisk, który przekieruje nas do usuwania jakiegoś obiektu z bazy, ale zanim to zrobi, spyta, czy na pewno tego chcemy.
Standardowa część interfejsu, możliwa do zrealizowania w webie na wiele różnych sposobów. Najprostszym z nich jest zwykłe okienko confirm().
W wersji najbardziej prymitywnej wykonanie zadania wygląda mniej więcej tak:
<a href="{{ route('product_delete', {id: product.id}) }}"
onclick="return confirm('{{ 'delete.confirm'|l|e }}')">
{{ 'delete'|l }}
</a>
Prosta sprawa – linkujemy do adresu, który usunie produkt z bazy, ale przy kliknięciu pytamy użytkownika, czy na pewno chce to zrobić. Jeśli nie chce, wtedy confirm() zwróci false, a więc wykonanie przekierowania zostanie zablokowane.
Jest z tym kodem tylko jeden problem – mieszamy ze sobą HTML i JS. A to nie tak powinny działać internety.
Poprawnie napisana strona internetowa składa się (oczywiście w części frontendowej) z trzech warstw:
- w HTML-u umieszczamy ustrukturyzowane dane,
- w CSS-ach definiujemy, jak te dane mają być prezentowane,
- a w JS-ie dodajemy wszystkie te fajerwerki i świecidełka, dzięki którym strona jest dynamiczniejsza i atrakcyjniejsza.
Najlepiej, gdyby warstwy te w ogóle się ze sobą nie mieszały. Dzięki temu kod jest czystszy, a warstwy mogą być używane i modyfikowane niezależnie od siebie. Można na przykład w banalnie prosty sposób zaimplementować różne skórki na stronie, po prostu podmieniając używany akrusz stylów na inny. Jeśli w HTML-u nie umieścimy żadnych stylów inline (mam nadzieję, że nikomu choć trochę znającemu temat nie trzeba tłumaczyć, jak zły jest to pomysł), lecz tylko dane oraz strukturę, w jakiej są ułożone, to całkowita zmiana wyglądu strony jest nadzwyczaj łatwa. (Dla przykładu choćby bootswatch.com albo csszengarden.com – wszystkie podstrony w dziale “themes” różnią się tylko jedną rzeczą: nazwą pliku .css)
Dokładnie to samo tyczy się JavaScriptu. Jeśli kod wykonywalny umieścimy bezpośrednio wewnątrz znacznika HTML, nasz kod staje się zdecydowanie mniej czytelny i bardziej narażony na powtarzalność. Wprowadzanie w nim potem zmian może się okazać drogą przez mękę. Powiedzmy, że po jakimś czasie zechcemy zmienić to brzydkie okienko confirm() na przykład na bootstrapowy modal. Będziemy wtedy musieli znaleźć wszystkie użycia podobnego kodu w naszym projekcie i przerobić każde z nich. Po co się tak męczyć?
Natknąłem się ostatnio na taki oto kod, mający wykonać nasze proste zadanie bez mieszania ze sobą warstw aplikacji:
<a class="js-delete-event"
href="javascript:void(0)"
data-delete-url="{{ route('product_delete', {id: product.id}) }}"
data-confirm-message="{{ 'delete.confirm'|l|e }}">
{{ 'delete'|l }}
</a>
Natomiast w pliku JavaScriptu:
$('.js-delete-event').on('click', function() {
if (true == confirm($(this).data('confirm-message'))) {
window.location.href = $(this).data('delete-url');
}
});
Wygląda na zdecydowanie bardziej skomplikowany niż powien być... Niby jest w porządku: w HTML-u nie mamy skryptów, a jedno z drugim komunikuje się za pomocą klas i atrybutów data, tak jak powinno być. HTML definiuje, że link jest klasy js-delete-event, dokąd powinien kierować i jak brzmi przetłumaczona prośba o potwierdzenie, natomiast JS szuka wszystkich elementów z klasą js-delete-event i podpina pod nie listenera, który o potwierdzenie faktycznie spyta, i w zależności od odpowiedzi, przekierowuje użytkownika do strony usuwającej, bądź też nie.
A jednak JS w tym HTML-owym kodzie się pojawia, i to w swojej najbrzydszej formie: jako pseudoprotokół. Link, zamiast kierować nas do rzeczywistej strony, odsyła nas do jakiegoś void(0) przez nieistniejący protokół javascript... Jest to zwykły zabieg mający na celu zablokowanie linka, skierowanie go donikąd, ale jakże strasznie psuje semantykę strony...
I ma w dupie Progressive enhancement. A to bardzo źle, mieć go w dupie...
W progressive enhancement chodzi mniej więcej o to, aby zapewnić dostęp do wszystkich podstawowych danych na stronie oraz do wszystkich podstawowych funkcji naszej aplikacji dla każdego użytkownika. Nawet jeśli używa IE6 albo nie daj bogini jakiegoś lynxa czy innej wyłącznie tekstowej przeglądarki. Natomiast im jego przeglądarka jest lepsza, nowocześniejsza i zgodniejsza ze standardami, tym więcej deweloper może zaszaleć z ładnym wyglądem i wodotryskami.
Nie zawsze użytkownikowi zadziałają skrypty. Może CDN z jakąś biblioteką zaszwankuje, może user jedzie pociągiem i mu net przerywa, a może po prostu sam je wyłączył (tak, niektórzy to robią).
Jak w takim przypadku zadziała powyższy kod? Ano właśnie, nie zadziała w ogóle. Chyba że user zajrzy w źródło strony, domyśli się, o co chodzi, i ręcznie przejdzie do URL-a podanego w atrybucie data-delete-url. Powodzenia.
A więc progressive enhancement leży. Dla pewnej grupy użytkowników dostęp do ważnej funkcjonalności jest niemożliwy.
Spójrzmy teraz na inny kod:
<a href="{{ route('product_delete', {id: product.id}) }}"
data-confirm="{{ 'delete.confirm'|l|e }}">
{{ 'delete'|l }}
</a>
$('a[data-confirm]').click(function() {
return confirm($(this).data('confirm'));
});
Tutaj mamy w HTML-u najzwyczajniejszy w świecie link, po prostu z jednym dodatkowym atrybutem. Gdyby z jakiegoś powodu nie załadował się skypt, świat się nie zawali. Użytkownik dalej ma możliwość usunięcia elementu, po prostu jest bardziej narażony na zrobienie tego przez przypadek, bo nie zobaczy potwierdzenia.
Jeśli natomiast JS działa, skrypt znajdzie wszystkie elementy posiadające atrybut data-confirm i podepnie pod nie listenera, zadającego użytkownikowi pytanie, które się w tym atrybucie znajduje.
Ten kod jest o wiele lepszy od poprzedniego nie tylko ze względu na respektowanie progressive enhancement:
- Element A został odchudzony ze wszystkich zbędnych atrybutów (czyli połowy!). W poprzednim kodzie jego autor udał, że link donikąd nie kieruje, tylko po to, by później przekazać odpowiedni URL w osbobnym atrybucie. Użył też specjalnej klasy, po której JS miał rozpoznać interesujące go elementy, mimo że sam fakt posiadania tekstu potwierdzenia już dostatecznie jasno identyfikuje elementy, które powinny wyświetlić potwierdzenie.
- Wykorzystanliśmy świetnego ficzera jQuery – to, że zwrócenie
falsew event hadlerze automatycznie zatrzymuje propagację zdarzenia. W bardzo elegancki i zwięzły sposób zatrzymaliśmy przekierowanie po kliknięciu, bez potrzeby uciekania się do pseudoprotokołów anievent.stoppropagation(); event.preventdefault();, przy okazji jeszcze pytając o zgodę użytkownika – w jednej prostej linijce! - Nie używamy okropnego
window.location.href. Pozwalamy na zwyczajną obsługę operacji przekierowania po kliknięciu w link, po prostu rozszerzając ją o możliwość warunkowego przerwania, zamiast sztucznie i nieelegancko blokować przekierowanie tylko po to, by potem jeszcze sztuczniej wywołać je od nowa...