When it comes to DevOps, I'm just the “dev”. I write code, but I'd rather have someone else worry about making sure it keeps running as intended. I manage my personal VPS, I manage some servers at work, but I wouldn't call myself an expert in that area at all. So I'm super proud of myself and how well it went when I migrated a big project to a new machine 😊 The downtime was just 15 minutes! Here's the story, if you're interested.
Why move?
- Pronouns.page gets lots of traffic: around 4 million pageviews a month for the English version alone. And on top of that, as an unapologetically queer website, we're a target of regular DDoS attacks. The previous server didn't handle it well. We need an upgrade.
- Pronouns.page used to run on my personal VPS together with all my other pet projects. They might not need many resources in comparison (damn, PP has outgrown everything else, including my wildest dreams 😅), but it's still gonna be useful to give PP dedicated resources.
- I used to be a bottleneck when it comes to fixing any issues on the server. Now that my personal stuff is on a different server, multiple people can have SSH access to the PP instance and intervene when necessary.
- We moved from OVH to Hetzner, getting a way better deal. Instead of 21.5€/m[1] for 2 vCPU, 8GB RAM and 130GB drive we'll now pay 27.25€/m for 8 vCPU, 16GB RAM and 240GB drive.[2]
- The cost can now be charged directly to the NLC account, I won't have to manage reimbusements (well, as soon as I figure out AWS migration).
- I could use the opportunity to migrate to a new stack, which would've been hard to do on a running server with tens of active projects.
The plan
I bought the server on Wednesday and started setting it up, completely independently of the old machine.
I created a setup that from the outside was indistinguishable from the old one, except for using an older database backup.
Until Saturday morning they were running simultaneously – the DNS were pointing to the old IP,
but my local /etc/hosts to the new one.
I picked Saturday morning, because mornings are when our traffic is lowest, and that day I'm free and can focus on the migration, even if something goes wrong and takes more time than expected.
An important part of the plan was taking notes – every important command I had run, I documented for myself. In case anything goes wrong and I have to start over, or in case I wanted to later migrate my other projects to Hetzner too (and I do), I'd have a recepe basically ready.
Cool things
The old configs were… meh. Long, repetitive and messy. Just switching from Apache to nginx simplified them massively, but I went further and extracted common parts for all domains and subdomains to make them reusable. Setting up everything for a new language version used to be a half-an-hour-or-so long process – now it takes me a few minutes.
There's two things that were really annoying for me to figure out: analytics and monitoring. Those things are expensive when your traffic is as big as ours. Corporations with such traffic can afford it easily, but we're not a business, we have no considerable income other than donations and an arc.io widget. We need to self-host those things, then.
For traffic analytics, I've recently switched from Matomo to Plausible. As much as Matomo is better than Google Analytics from the privicy perspective (and it's a lot better), it's still really heavy and has way more features than I'll probably ever need. I needed to pay 11€/m extra for a separate database server just for Matomo to store its logs. Plausible, on the other hand, is exactly what I need. So neat!
For monitoring… We used to have one, hosted on AWS Lambda, but it kept causing trouble that I had no time to fix, and in the end I disabled it. Monitoring is quite hard, because it needs to run on a dedicated and super reliable infrastructure – we can't monitor ourselves after all; if the server is down, so is the monitor that's supposed to let us know. I found out a really cool tool that keeps blowing my mind with its ingenuity: Upptime. It runs entirely on GitHub pages and actions, totally for free (as long as you keep it public).
Issues
We have multiple node servers running for different language versions. Each needs to run at some port and then nginx needs to be configured as a reverse proxy to that specific port. Before it was really tediuos, I'd just enumerate the ports starting at 3001 and for each new version I'd first need to sift through configs to find what the current max value was. I kept looking up which port was related to which domain. Annoying shit.
In the new setup, I wanted to have some single source of truth for the domain-port pairs, but it turned out to be near impossible (at least for my skills). Nginx is strict about its configs being static. I couldn't find an easy way to pass data about those ports to it.
Ultimately, I settled for a compromise system: I unambiguously map each version to a port
by convering each letter of its ISO code to its index in the English alphabet.
For example for Japanese, ja, the port would be 31001 because “j” is the 10th letter of the alphabet,
and “a” is the 1st. Not a perfect system, but it's gonna simplify my flow a lot.
I wanted to switch from supervisor to pm2 for its nicer interface and cool features, but for some reason it kept dropping a significant percentage of requests at (seemingly) random. I couldn't figure out the root cause, so I gave up. That switch wasn't worth that much of my time, I reverted back to supervisor.
A huge issue was that… no emails were getting sent from the new server. Every SMTP request would just time out. I tried everything I could think of, I figured I must've misconfigured something. I asked the team for help, but we couldn't find a root cause. But then I got this random hypothesis – what if Hetzner is blocking port 465 regardless of our firewall settings? A quick seach – turns out they do! Ugh… I get their reasoning, seems like a perfectly reasonable approach. Switching ports worked. I just wish they somehow gave notice more visibly, not just an unexplained timeout, so that I wouldn't waste so much time figuring it out.
I struggled with moving Plausible too… It runs in Docker containers – but my knowlege of Docker is pretty limited.
I spent way too much time trying to pg_dump and pg_restore my way from one container to host to another host via scp
to another container, only to finally succeed and then… realise that the Postgres database is just half of the story.
The main chunk of data resides in ClickHouse.
Instead of struggling with the whole thing again, I took a different approach: backing up and restoring entire Docker volumes.
It worked like a charm! Here are the commands, if you're interested:
# old host
docker run -v plausible_db-data:/volume --rm loomchild/volume-backup backup - > ./db-data.tar.bz2
docker run -v plausible_event-data:/volume --rm loomchild/volume-backup backup - > ./event-data.tar.bz2
scp ./db-data.tar.bz2 pp:/home/admin/www/stats.pronouns.page
scp ./event-data.tar.bz2 pp:/home/admin/www/stats.pronouns.page
# new host
cat ./db-data.tar.bz2 | sudo docker run -i -v statspronounspage_db-data:/volume --rm loomchild/volume-backup restore -f -
cat ./event-data.tar.bz2 | sudo docker run -i -v statspronounspage_event-data:/volume --rm loomchild/volume-backup restore -f -The switch
When everything was ready, on Friday evening, I announced the upcoming maintanance and waited. I had all the commands ready in a notepad.
When the time came, I just… stopped both servers, moved the database, moved plausible volumes, started the new server, and then updated the DNS entries. Simple as that.
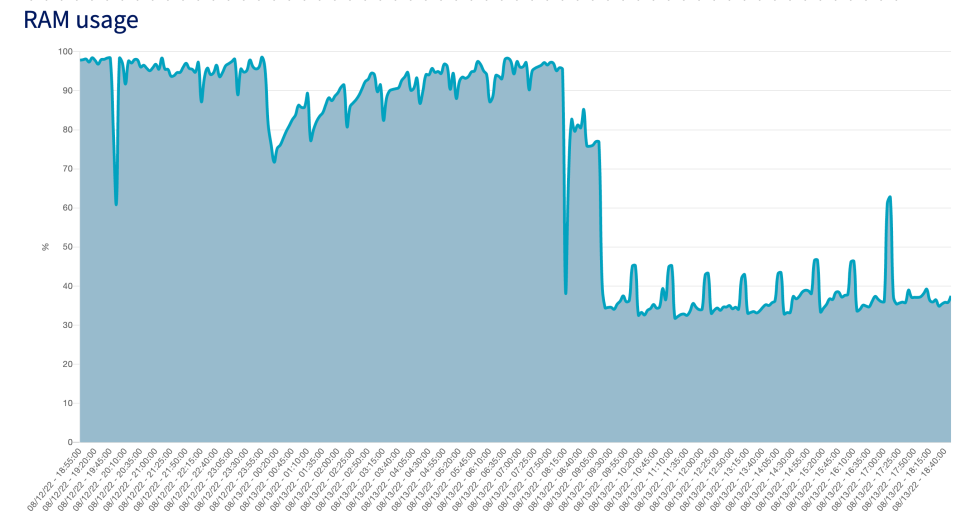
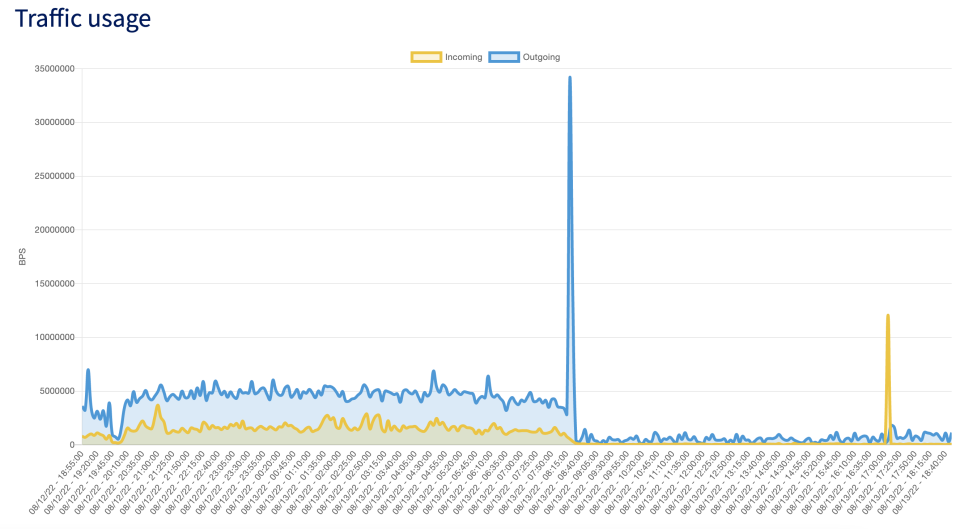
It was tons of work over a couple of evenings, but good preparation made wonders: it only took a quarter to actually switch. Considering how ops is not my forte at all, I'm so proud of having accomplished such a smooth transition 🥰

- [1] Or more precisely: 80% of the old price (based on traffic ratio), was paid by NLC and 20% by me – now that it's just my personal server again I'm gonna pay 100% 😅
- [2] That's just VPS costs, AWS bill is a whole other story.